Notification Engine as a Microservice
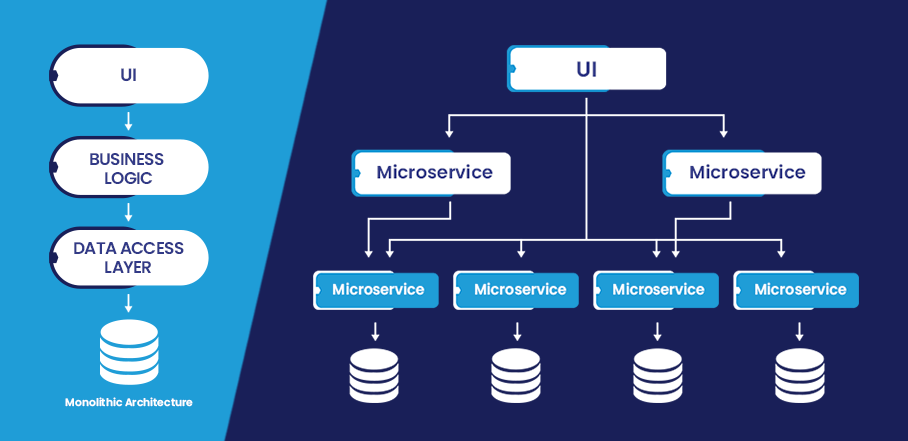
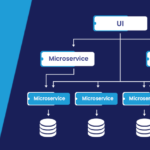
Microservice architecture
Rubique has developed a communication platform in house to notify its customers and associates of every
significant event in the loan, card or insurance journey without overwhelming him/her with too many
notification.
Our customer research indicates that the key challenge faced by the customers or the associates is the lack of
transparency and real time intimation and status of their financial application. We as a financial marketplace
have built lending gateways and integrated with financial institutions to help our partners query the status of
their financial application in real time. While this works for our strategy alliances, we realized that customer
hates to login into any app or platform to check the status and hence it is extremely important to have a push
mode of communication in real time rather than a pull mode of communication.
In the pursuit to solve this problem and have better transparency through the financial application, we developed
a communication platform that is based on Facebook Activity Stream pattern. Every activity in the system is
published into a notification engine along with all the relevant data. It then allows product and business teams
to specify at what event and activity, would they want to initiate the communication and at what frequency to
sufficiently engage the customer without overwhelming him with irrelevant and redundant communications. The
product team can also control what mode of communication would they want to use at every event — SMS, Email, Web
Notifications or Push Notifications. It uses template engine and hence separates view from data. Marketing team
could hence configure the communication message without worrying about the code and this flexibility allows them
to AB test various interactions to find out what is more relevant to the customer or the associates.
We use the same underlying architecture to push offers to the customers to reengage him for cross sell and upsell
and we see much higher engagements. As a next step and enhancement, we are in the process of integrating it with
webengage to further leverage the flexibility of the platform developed and do more customized AB tests to drive
higher conversions and better customer engagements. The other advantage of this platform is that timely
communications greatly helped us reduce queries to our customer support team, thereby promoting self serving of
customers and associates.
Technology Stack
We at Rubique believe in polyglot architecture and polyglot data stores and same is reflected in the technology
choices that we made for designing our Rubique platform. MEAN stack sits at the heart of the Rubique technology
and we primarily use NodeJs coupled with Express REST Framework.
While RDS forms the backbone of our data store, user profiles and certain unstructured data are stored in Mongo
DB. Elastic Cache is predominantly used for session management and caching infrequently changing data.
APIs are expressed through the API gateway which sits behind Amazon ELB. Amazon ELB does all heavy lifting like
preventing DDOS, SSL Offloading, DNS Resolution, etc leaving the APIs to focus on core application and business
logic.
Kafka as Message Queue. Why?
The need for microservices to communicate with each other, many of which does not necessitate real time
communication, demanded the need of a PUB SUB engine that can help producers notify the consumers of the event
without bothering about the health and response of consumers.
While we evaluated many queueing solution like ActiveMQ, RabbitMQ, etc, we ended up using Kafka. While RabbitMq
came closest to Kafka, the lack of proper clustering support in RabbitMq served as an elimination factor.
Kafka is a great fit for many use cases, mostly for website activity tracking, log aggregation, operational
metrics, stream processing and, in our case, for notification. It is a highly durable messaging system. Kafka is
unique in the way it handles messages. It stores each topic partition as a log (that is, an ordered set of
messages), and that every message within a given partition is assigned a unique offset. Kafka doesn’t track
which message was actually read by what consumer and doesn’t just hold on to unread messages. Instead, it holds
all of the messages for a pre-specified amount of time which can be defined in kafka configuration settings and
consumers itself check their offset from the file and start reading the message from the offset. Since the
message store and read is made simple, it supports huge amount of data and consumers without much overhead. We
benchmarked Kafka for 1 million events per second and that was enough for our use case for the next 2 years.
Architecture and Design
At Rubique, we use Express framework for our back-end APIs (mainly due to asynchronous nature). MySQL as our
relational database , mongodb as nosql database, redis for caching. We use ELK stack for Logging purpose. For
implementing Kafka in our system we used a node-library kafka-node.
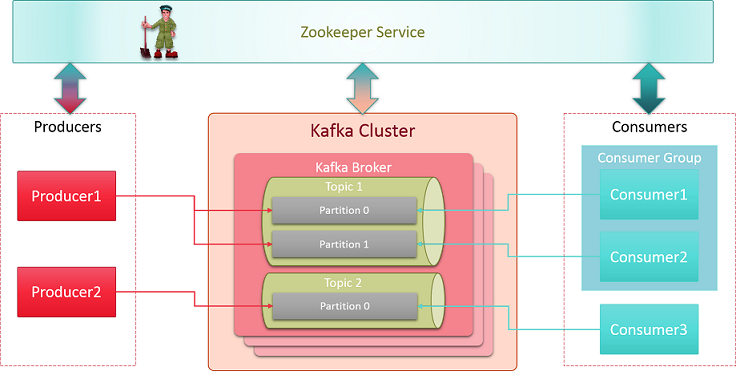
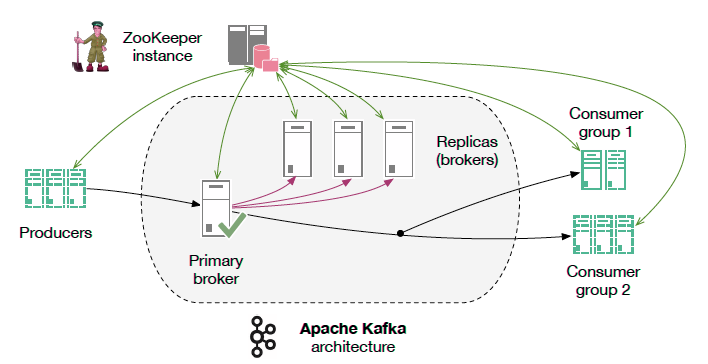
Kafka Internal Architecture
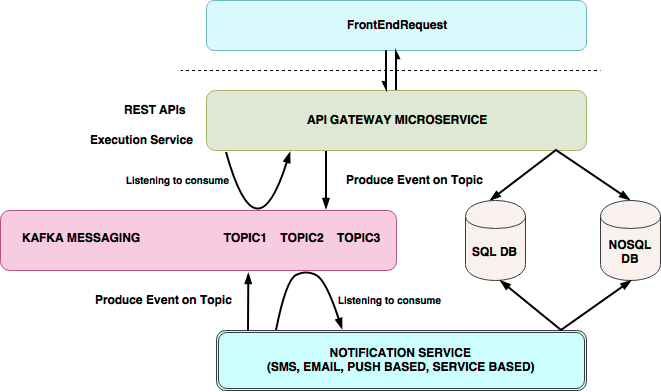
Notification engine comprises of 2 services with one of them as our Notification Engine and other acts as the
parent Service. For sending a notification through our service we stored event topic mappings in our SQL
Database. This mapping is used to publish an event on a particular topic. We also stored templates and channel
information mapped with an event in another schema. “When an event occurs, the producer fetches the
corresponding topic from the SQL database and publishes it on a Kafka-broker. The consumer keeps listening to
this broker/queue.
When events get published consumer pulls the message(it contains event name) on the basis of which channel and
template are fetched from the database. Channel can be defined as a mode of notification. The templates are then
rendered on the run time using the data published by producer and metadata fetched depending on the type of user
and a final draft is generated to send. After the notification is sent, this event is published on Parent
service to log the sent notification in a NoSQL database.
For now, a single partition is used for implementation. We also had configured the limit on the size of the
message fetched from the message queue and also set auto-commit mode as true. It means once a message is pulled
from broker it automatically updates the offset of kafka log store to a new value and next time consumer pulls
at that particular offset. Picture below demonstrates the workflow.
Context Setting
One of the key requirement in any generic communication engine platform is the need to be able to keep the
presentation layer separate from the data layer and have the access to custom data dynamically and on the fly,
We achieved this by writing an elaborate routine that provides access to the entire lead and customer data based
on parameter. Along with this, the data logged in the form of an activity is also available to the templates to
be used thus allowing custom communications to be sent.
API Gateway
While the above configuration and architectural choice served most of our needs, one limitation that we faced was
the ability to call REST services directly based on certain events. And this is what we achieved by API gateway.
API gateway allows abstraction so that notification service can call the API based on events without being aware
of all that is happening under the hood.
Conclusion
While we are happy with what we have done, the next enhancement that we are thinking of is deploying each
microservice as part of auto scaling group and services being able to call each other without being aware of
where they are running. We are exploring Kubernetes along with Consul for this.